Would you like to hear about webinars we're
doing, new features we're adding and projects we're undertaking? Sign up
here to our pleasantly infrequent newsletter!
Moveshelf is designed to keep data secure but always
accessible. This is true both from our web interface, for physicians and
clinical operators, as well as programmatically from our API, for
engineers and scientists.
This chapter contains all information to get
started with the Moveshelf Python API (from now on referred to as Moveshelf API).
The Moveshelf API simplifies integration with Moveshelf
for Python developers. It abstracts authentication, request handling, and common tasks into an intuitive, high-level interface,
allowing developers to focus on building solutions without needing to manage the complexities of API interactions.
The Moveshelf API enables seamless data retrieval and manipulation while integrating naturally with Python's ecosystem
of libraries. This makes it an ideal choice for automating workflows, processing data, and creating custom scripts that interact
with Moveshelf resources. This
documentation is intended for engineers, researchers, and advanced users who
want to automate workflows and build custom solutions using the Moveshelf API.
How to use this documentation
Our goal is to break down import and querying steps into modular "puzzle pieces" that
can be combined to create custom workflows.
To begin, read how you can set up your programming environment,
the Moveshelf API, and a GitHub repository.
Then, learn how to configure the Moveshelf API and where to find a link to the
complete documentation. Finally, experiment with specific examples
to get started. Each example includes prerequisites that must be completed before implementation.
A complete overview of this chapter's sections is available in the navigation menu on the left.
To help you get started even faster, we also provide a recording of a live training session that introduces the basic
data import workflow. You can watch it here:
▶ Moveshelf training - How to import historical data.
To interact with the Moveshelf API, you need Python and an integrated development environment (IDE) such as Visual Studio Code, PyCharm, or Spyder. This setup will allow you to run existing Python scripts from GitHub or create your own. This section walks you through setting up your environment to interact with the Moveshelf API using Python, and running a python script. While you can use any IDE that supports Python, this documentation provides instructions and examples specifically for Visual Studio Code.
While using a Git repository is not required to use the Moveshelf API, it provides easy access to public resources from Moveshelf, e.g., moveshelf-data-examples. This section explains how to clone a GitHub repository and install its dependencies.
Install Git
Install the lastest version of Git on your computer.
Clone a GitHub repository to your local machine
Create an account on GitHub to be able to use the public repositories
Select a local folder where you want to clone the repository
Install dependencies
To ensure your Python script runs without errors, it's best practice to list all required modules (along with their versions) in a requirements.txt file. To install these dependencies automatically:
Open a new terminal in Visual Studio Code
Run the command: pip install -r requirements.txt in the terminal and press 'Enter'
Make sure your terminal is in the correct folder where the requirements are saved as well.
To help you get started even faster, we provide a recording of a live training session that demonstrates how to install and configure the Moveshelf API, and how to create a Python script from scratch to import data from a session to a newly created subject on Moveshelf. You can access the full video here:
▶ Moveshelf training - How to import historical data.
While this page covers a variety of examples of basic and advanced API usage, you can find a complete overview of the functions that are available
in the Moveshelf API here.
Add the following lines of code to your processing script to use the Moveshelf API:
importos,sys,jsonparent_folder=os.path.dirname(os.path.dirname(__file__))sys.path.append(parent_folder)frommoveshelf_api.apiimportMoveshelfApifrommoveshelf_apiimportutil## Setup the API
# Load config
personal_config=os.path.join(parent_folder,"mvshlf-config.json")ifnotos.path.isfile(personal_config):raiseFileNotFoundError(f"Configuration file '{personal_config}' is missing.\n""Ensure the file exists with the correct name and path.")withopen(personal_config,"r")asconfig_file:data=json.load(config_file)custom_timeout=<nSeconds># timeout (integer) for HTTP calls. Defaults to 120 if undefined
api=MoveshelfApi(api_key_file=os.path.join(parent_folder,data["apiKeyFileName"]),api_url=data["apiUrl"],timeout=custom_timeout,)
In this example we are going to use a built-in function of the Moveshelf API to retrieve the projects the current user has access to.
Add the following line of code to get a list of all the projects that are accesible by the user:
## Get available projects
projects=api.getUserProjects()
To make your life easier, we have created a list of example use cases for the Moveshelf API. Each example has a dedicated section and is explained in detail later on this page.
Refer to the following sections for example use cases for importing data:
This section explains how to create a new subject on Moveshelf using the Moveshelf API, based on the subject's MRN/EHR-ID. Before creating a new subject, the script first checks whether a subject with the given MRN/EHR-ID already exists on Moveshelf.
If a matching subject is found, it is retrieved
If no existing subject is found, a new subject is created and assigned the specified MRN/EHR-ID
Prerequisites
Before implementing this example, ensure that your processing script includes all necessary setup steps. In particular, you should have:
To create a new subject or retrieve an existing one, add the following lines of code to your processing script:
## README: this example shows how we can create a subject on Moveshelf
# using the Moveshelf Python API.
# For a given project (my_project), first check if there already exists
# a subject with a given MRN (my_subject_mrn). If it doesn't exist,
# we create a new subject with name my_subject_name, and assign my_subject_mrn if provided.
## General configuration. Set values before running the script
my_project="<organizationName/projectName>"# e.g. support/demoProject
my_subject_mrn="<subjectMRN>"# subject MRN, e.g. "1234567", set to None if not needed.
my_subject_name="<subjectName>"# subject name, e.g. Subject1
## Get available projects
projects=api.getUserProjects()## Select the project
project_names=[project["name"]forprojectinprojectsiflen(projects)>0]idx_my_project=project_names.index(my_project)my_project_id=projects[idx_my_project]["id"]## Find the subject based on MRN
subject_found=Falseifmy_subject_mrnisnotNone:subject=api.getProjectSubjectByEhrId(my_subject_mrn,my_project_id)ifsubjectisnotNone:subject_found=True## Retrieve subject details if there was a match. Create new subject if there is no match
ifsubject_found:subject_details=api.getSubjectDetails(subject["id"])subject_metadata=json.loads(subject_details.get("metadata","{}"))print(f"Found subject with name: {subject_details['name']},\n"f"id: {subject_details['id']}, \n"f"and MRN: {subject_metadata.get('ehr-id',None)}")else:print(f"Couldn't find subject with MRN: {my_subject_mrn},\n"f"in project: {my_project}")new_subject=api.createSubject(my_project,my_subject_name)ifmy_subject_mrnisnotNone:subject_updated=api.updateSubjectMetadataInfo(new_subject["id"],json.dumps({"ehr-id":my_subject_mrn}))
Validation
To verify that the new subject has been successfully created, you can either check directly on Moveshelf or programmatically via the Moveshelf API.
For the manual validation, log in to Moveshelf and navigate to the relevant project to check if the new subject appears with the correct MRN/EHR-ID.
If you prefer an automated method, add the following lines of code to your processing script, right after creating the new subject, to check the subject’s details programmatically:
# Fetch subject details using the subject ID
new_subject_details=api.getSubjectDetails(new_subject["id"])new_subject_metadata=json.loads(new_subject_details.get("metadata","{}"))# Print the subject details
print(f"Created subject with name: {new_subject_details['name']},\n"f"id: {new_subject_details['id']}, \n"f"and MRN: {new_subject_metadata.get('ehr-id',None)}")
This code will retrieve the newly created subject's details, including the name, ID, and MRN/EHR-ID, and print them for verification.
This example demonstrates how to import subject metadata for an existing subject on Moveshelf via the Moveshelf API.
First we retrieve the subject from Moveshelf via its MRN/EHR-ID. Then, we update its subject metadata.
Important: The keys in the metadata dictionary to be imported must match the metadata template that is configured for the Moveshelf project you want to import to. You can download the configured metadata template from the project overview.
Moreover, updating metadata through the Moveshelf API behaves the same way as performing a directory upload via the web interface using 'moveshelf_config_import.json':
Existing subject metadata values are not overwritten. Only empty fields are updated.
However, existing interventions will be overwritten.
Prerequisites
Before implementing this example, ensure that your processing script includes all necessary setup steps. In particular, you should have:
Created the subject, or made sure a subject with the specified MRN already exists on Moveshelf
Implementation
To import subject metadata to an existing subject, add the following lines of code to your processing script:
## README: this example shows how we can import subject metadata to an existing
# subject on Moveshelf using the Moveshelf Python API.
# This code assumes you have implemented the 'Create subject' example, and
# that you have found the subject with a given EHR-id/MRN (my_subject_mrn)
# within a given project (my_project), and that
# you have access to the subject ID
# For that subject, update subject metadata (my_subject_metadata)
## General configuration. Set values before running the script
my_project="<organizationName/projectName>"# e.g. support/demoProject
my_subject_mrn="<subjectMRN>"# subject MRN, e.g. "1234567" or None
# Manually define the subject metadata dictionary you would like to import
my_subject_metadata={"subject-first-name":"<subjectFirstName>","subject-middle-name":"<subjectMiddleName>","subject-last-name":"<subjectLastName>","ehr-id":my_subject_mrn,"interventions":[# List of interventions
{"id":0,# <idInterv1>
"date":"<dateInterv1>",# "YYYY-MM-DD" format
"site":"<siteInterv1>","surgeon":"<surgeonInterv1>","procedures":[{"side":"<sideProc1Interv1>","location":"<locationProc1Interv1>","procedure":"<procedureProc1Interv1>","location-modifier":"<locationModProc1Interv1>","procedure-modifier":"<procedureModProc1Interv1>"},{"side":"<sideProc2Interv1>",# ... You can add multiple procedures
}],"surgery-dictation":"<surgeryDictationInterv1>"},# ... Additional interventions can be added here, each represented as a dictionary
# Increment the "id" for each new intervention (e.g., 1, 2, 3,...)
# Ensure each intervention contains a complete set of fields
]# ... Add additional fields you would like to import
}## Add here the code to retrieve the project and find an existing subject and its "subject_details"
# ... subject_found = True
# Import subject metadata
subject_updated=api.updateSubjectMetadataInfo(subject["id"],json.dumps(my_subject_metadata))
It is also possible to load subject metadata from a JSON file stored on your local machine, e.g., 'moveshelf_config_import.json'. Instead of defining my_subject_mrn and my_subject_metadata manually, you can load them from a JSON file located in your root folder as shown below:
# Define the path to the local JSON file
local_metadata_json=os.path.join(parent_folder,"moveshelf_config_import.json")# Load JSON file
withopen(local_metadata_json,"r")asfile:local_metadata=json.load(file)# Extract subjectMetadata dictionary from metadata JSON
my_subject_metadata=local_metadata.get("subjectMetadata",{})my_subject_mrn=my_subject_metadata.get("ehr-id","")# Extract interventionMetadata list from metadata JSON
my_subject_metadata["interventions"]=local_metadata.get("interventionMetadata",[])
Validation
To verify that the subject metadata has been successfully imported, you can either check directly on Moveshelf or programmatically via the Moveshelf API.
For the manual validation, log in to Moveshelf and navigate to the relevant project to check if the subject appears with the correct subject metadata.
If you prefer an automated method, add the following lines of code to your processing script, right after updating subject metadata, to check the subject’s metadata programmatically:
# Fetch subject details using the subject ID
subject_details=api.getSubjectDetails(subject["id"])subject_metadata=json.loads(subject_details.get("metadata","{}"))# Print the subject details
print(f"Updated subject with name: {subject_details['name']},\n"f"id: {subject_details['id']}, \n"f"and metadata: {subject_metadata}")
This code will retrieve the subject's details, including the name, ID, and subject metadata, and print them for verification.
This section explains how to create a new session for a subject with a specified MRN on Moveshelf using the Moveshelf API, based on the session's name and date. Before creating a new session, the script first checks whether a session with the specified name already exists for that subject on Moveshelf.
If a matching session is found, it is retrieved
If no existing session is found, a new session is created and assigned the specified name (my_session_name) and date (my_session_date)
Prerequisites
Before implementing this example, ensure that your processing script includes all necessary setup steps. In particular, you should have:
Created the subject, or made sure a subject with the specified MRN already exists on Moveshelf
Implementation
To create a new session or retrieve an existing one, add the following lines of code to your processing script:
## README: this example shows how we can create a session on Moveshelf
# using the Moveshelf API.
# This code assumes you have implemented the 'Create subject' example, and
# that you have found the subject with a given EHR-id/MRN (my_subject_mrn)
# within a given project (my_project), and that you have access to the subject ID
# For that subject, we check if a session with the specified name
# (my_session_name) exists. If it doesn't exist, a new session is created with the specified
# name (my_session_name) and date (my_session_date).
## General configuration. Set values before running the script
my_project="<organizationName/projectName>"# e.g. support/demoProject
my_subject_mrn="<subjectMRN>"# subject MRN, e.g. "1234567" or None
my_session_name="YYYY-MM-DD"# session name, e.g. 2025-09-05
my_session_date="YYYY-MM-DD"# typically the same as session name, e.g. 2025-09-05
## Add here the code to retrieve the project and find an existing subject and its "subject_details"
# ... subject_found = True
## Find existing session
sessions=subject_details.get('sessions',[])session_found=Falseforsessioninsessions:try:session_name=session['projectPath'].split('/')[2]except:session_name=""ifsession_name==my_session_name:session_id=session['id']session=api.getSessionById(session_id)# get all required info for that session
session_found=Trueprint(f"Session {my_session_name} already exists")break## Create new session if no match was found
ifnotsession_found:session_path="/"+subject_details['name']+"/"+my_session_name+"/"session=api.createSession(my_project,session_path,subject_details['id'],my_session_date)session_id=session['id']
Validation
To verify that the new session has been successfully created, you can either check directly on Moveshelf or programmatically via the Moveshelf API.
For the manual validation, log in to Moveshelf and navigate to the relevant project and subject to check if the new session appears with the correct name.
If you prefer an automated method, add the following lines of code to your processing script, right after creating the new session, to check the session’s details programmatically:
# Fetch session details using the session ID
new_session=api.getSessionById(session_id)print(f"Found session with projectPath: {new_session['projectPath']},\n"f"and id: {new_session['id']}")
This code will retrieve the newly created session's details, including the project path (that includes the subject name and the session name), and ID, and print them for verification.
This example demonstrates how to import session metadata for an existing session on Moveshelf via the Moveshelf API.
First we retrieve the subject from Moveshelf via its MRN/EHR-ID. Then, we retrieve the session via its session date, and update its metadata.
Important: The keys in the metadata dictionary to be imported must match the metadata template that is configured for the Moveshelf project you want to import to. You can download the configured metadata template from the project overview.
Moreover, updating metadata through the Moveshelf API behaves the same way as performing a directory upload via the web interface using 'moveshelf_config_import.json', i.e., existing session metadata values are not overwritten. Only empty fields are updated.
Prerequisites
Before implementing this example, ensure that your processing script includes all necessary setup steps. In particular, you should have:
Created the session, or made sure a session with the specified date already exists on Moveshelf
Implementation
To import session metadata to an existing subject and session, add the following lines of code to your processing script:
## README: this example shows how we can import session metadata to an existing
# session on Moveshelf using the Moveshelf Python API.
# This code assumes you have implemented the 'Create session' example, and
# that you have found the session (my_session_name) for a subject with a given
# EHR-id/MRN (my_subject_mrn) within a given
# project (my_project), and that you have access to the session ID and session_name
# For that session, update session metadata (my_session_metadata)
## General configuration. Set values before running the script
my_project="<organizationName/projectName>"# e.g. support/demoProject
my_subject_mrn="<subjectMRN>"# subject MRN, e.g. "1234567" or None
my_subject_name="<subjectName>"# subject name, e.g. Subject1
my_session_name="<sessionDate>"# "YYYY-MM-DD" format
# Manually define the session metadata dictionary you would like to import
my_session_metadata={"interview-fms5m":"1","vicon-leg-length":[{"value":"507","context":"left"},{"value":"510","context":"right"}],# ... Add additional fields you would like to import
}## Add here the code to retrieve the project and find an existing subject
## and existing session
# loop over sessions until we find session_found = True
updated_session=api.updateSessionMetadataInfo(session_id,session_name,json.dumps({"metadata":my_session_metadata}))print(f"Updated session {session_name}: {updated_session}")
It is also possible to load session metadata from a JSON file stored on your local machine, e.g., 'moveshelf_config_import.json'. Instead of defining my_subject_mrn and my_session_metadata manually, you can load them from a JSON file located in your root folder as shown below:
# Define the path to the local JSON file
local_metadata_json=os.path.join(parent_folder,"moveshelf_config_import.json")# Load JSON file
withopen(local_metadata_json,"r")asfile:local_metadata=json.load(file)# Extract subjectMetadata dictionary from metadata JSON
my_subject_metadata=local_metadata.get("subjectMetadata",{})my_subject_mrn=my_subject_metadata.get("ehr-id","")# Extract sessionMetadata dictionary from metadata JSON
my_session_metadata=local_metadata.get("sessionMetadata",{})
Validation
To verify that the session metadata has been successfully imported, you can either check directly on Moveshelf or programmatically via the Moveshelf API.
For the manual validation, log in to Moveshelf and navigate to the relevant project to check if the session appears with the correct session metadata.
If you prefer an automated method, add the following lines of code to your processing script, right after updating session metadata, to check the session’s metadata programmatically:
# Fetch session details using the session ID
updated_session_details=api.getSessionById(session_id)updated_session_metadata=updated_session_details.get("metadata",None)# Print updated session metadata
print(f"Updated session with projectPath: {session['projectPath']},\n"f"id: {session_id}.\n"f"New metadata: {updated_session_metadata}")
This code will retrieve the updated session's details, including the projectPath, ID, and session metadata, and print them for verification.
This section explains how to create a new trial in a condition of a session for a subject with a specified MRN on Moveshelf using the Moveshelf API. Before creating a new trial, the script first checks whether a trial with the specified name already exists within the condition on Moveshelf.
If a matching trial in that condition is found, it is retrieved
If no existing trial with that name in the condition is found, a new trial is created
Prerequisites
Before implementing this example, ensure that your processing script includes all necessary setup steps. In particular, you should have:
Created the subject, or made sure a subject with the specified MRN already exists on Moveshelf
Created the session, or made sure a session with that name in the subject already exists on Moveshelf
Implementation
To create a new trial or retrieve an existing one, add the following lines of code to your processing script:
## README: this example shows how we can create a trial on Moveshelf
# using the Moveshelf API.
# This code assumes you have implemented the 'Create subject' example,
# that you have found the subject with a given EHR-id/MRN (my_subject_mrn)
# within a given project (my_project), and that you have
# access to the subject ID
# This code also assumes you have implemented the 'Create session' example,
# and that you have found the session with a specific name (my_session_name)
# For that subject and session, to understand if we need to create a new trial or find an
# existing trial, we first check if a condition with the specified name (my_condition)
# exists. If it doesn't exist yet, or if a trial with a specific name (my_trial) is not found
# in the existing condition, we create a new trial. Otherwise, we use the exising trial.
## General configuration. Set values before running the script
my_project="<organizationName/projectName>"# e.g. support/demoProject
my_subject_mrn="<subjectMRN>"# subject MRN, e.g. "1234567" or None
my_subject_name="<subjectName>"# subject name, e.g. Subject1
my_session_name="<sessionDate>"# "YYYY-MM-DD" format
my_condition="<conditionName>"# e.g. "Barefoot"
my_trial="<trialName>"# when set to None, we increment the trial number starting with "Trial-1"
## Add here the code to retrieve the project and find an existing subject and its "subject_details"
# ... subject_found = True
## Add here the code to retrieve an existing session and get its details using "getSessionById"
# Get conditions in the session
conditions=[]conditions=util.getConditionsFromSession(session,conditions)condition_exists=any(c["path"].replace("/","")==my_conditionforcinconditions)condition=next(cforcinconditionsifc["path"].replace("/","")==my_condition) \
ifcondition_existselse{"path":my_condition,"clips":[]}clip_id=util.addOrGetTrial(api,session,condition,my_trial)print(f"Clip created with id: {clip_id}")
It is also possible to load the condition names and list of trials from a JSON file stored on your local machine, e.g., 'moveshelf_config_import.json'. Instead of defining my_condition and my_trial manually, you can access them from a JSON file located in your root folder as shown below:
# Define the path to the local JSON file
local_metadata_json=os.path.join(parent_folder,"moveshelf_config_import.json")# Load JSON file
withopen(local_metadata_json,"r")asfile:local_metadata=json.load(file)# Extract conditionDefinition from metadata JSON
my_condition_definition=local_metadata.get("conditionDefinition",{})## Add here the code to retrieve the project and find an existing subject and its "subject_details"
# ... subject_found = True
## Add here the code to retrieve an existing session and get its details using "getSessionById"
# Get conditions in the session
conditions=[]conditions=util.getConditionsFromSession(session,conditions)# loop over conditions defined in conditionDefinition
formy_condition,my_trialsinmy_condition_definition.items():condition_exists=any(c["path"].replace("/","")==my_conditionforcinconditions)condition=next(cforcinconditionsifc["path"].replace("/","")==my_condition) \
ifcondition_existselse{"path":my_condition,"clips":[]}# Loop over trials list defined for my_condition
formy_trialinmy_trials:clip_id=util.addOrGetTrial(api,session,condition,my_trial)print(f"Clip created with id: {clip_id}")
Validation
To verify that the new trial has been successfully created, you can either check directly on Moveshelf or programmatically via the Moveshelf API.
For the manual validation, log in to Moveshelf and navigate to the relevant project, subject and session to check if the new trial appears with the correct name.
If you prefer an automated method, add the following lines of code to your processing script, right after creating the new trial, to check the trial details programmatically:
# Fetch trial using the trial ID
new_clip=api.getClipData(clip_id)print(f"Found a clip with title: {new_clip['title']},\n"f"and id: {new_clip['id']}")
This code will retrieve the newly created trial details, including the title and ID, and print them for verification.
This section explains how to upload data into a specific trial in a condition of a session for a subject with a specified MRN on Moveshelf using the Moveshelf API. Before uploading, the script first checks whether data file with the same name already exists within the trial on Moveshelf and will skip the upload if it's already present. Please refer to this section for supported data types.
Prerequisites
Before implementing this example, ensure that your processing script includes all necessary setup steps. In particular, you should have:
Created the subject, or made sure a subject with the specified MRN already exists on Moveshelf
Created the session, or made sure a session with that name in the subject already exists on Moveshelf
Created the trial, or made sure a trial with that name in the session already exists on Moveshelf
Implementation
To upload data into the trial identified by the "clip_id", add the following lines of code to your processing script:
## README: this example shows how we can upload date into a trial on
# Moveshelf using the Moveshelf API.
# This code assumes you have implemented the 'Create subject' example,
# that you have found the subject with a given EHR-id/MRN (my_subject_mrn)
# within a given project (my_project), and that you have access to the subject ID.
# This code also assumes you have implemented the 'Create session' example,
# and that you have found the session with a specific name (my_session_name)
# This code also assumes you have implemented the 'Create trial' example,
# and that you have found the trial with a specific name (my_trial).
# For that trial as part of a subject and session, we need the "clip_id".
## General configuration. Set values before running the script
my_project="<organizationName/projectName>"# e.g. support/demoProject
my_subject_mrn="<subjectMRN>"# subject MRN, e.g. "1234567" or None
my_subject_name="<subjectName>"# subject name, e.g. Subject1
my_session_name="<sessionDate>"# "YYYY-MM-DD" format
my_condition="<conditionName>"# e.g. "Barefoot"
my_trial="<trialName>"filter_by_extension=Nonedata_file_name=None# with None, the name of the actual file is used, if needed this name can be used
files_to_upload=[<pathToFile_1>,<pathToFile2>,...]# list of files to be added to the trial
data_type="raw"## Add here the code to retrieve the project and find an existing subject and its "subject_details"
# ... subject_found = True
## Add here the code to retrieve an existing session and get its details using "getSessionById"
## Add here the code to retrieve an existing trial and get the ID: clip_id
existing_additional_data=api.getAdditionalData(clip_id)existing_additional_data=[datafordatainexisting_additional_dataifnotfilter_by_extensionoros.path.splitext(data["originalFileName"])[1].lower()==filter_by_extension]existing_file_names=[data["originalFileName"]fordatainexisting_additional_dataiflen(existing_additional_data)>0]## Upload data
forfile_to_uploadinfiles_to_upload:file_name=data_file_nameifdata_file_nameisnotNoneelseos.path.basename(file_to_upload)iffile_nameinexisting_file_names:print(file_name+" was found in clip, will skip this data.")continueprint("Uploading data for : "+my_condition+", "+my_trial+": "+file_name)dataId=api.uploadAdditionalData(file_to_upload,clip_id,data_type,file_name)
Please note that the example above will skip the data upload of local files that have the same name as already existing files on Moveshelf. Alternatively, if you want to skip file upload only when the same version of your local file (not just the filename) has already been uploaded to Moveshelf, you can use the isCurrentVersionUploaded function and replace the Upload data section of the example above by:
## Upload data
forfile_to_uploadinfiles_to_upload:file_name=data_file_nameifdata_file_nameisnotNoneelseos.path.basename(file_to_upload)# Check if on Moveshelf there is already the same version of your local local file
is_current=api.isCurrentVersionUploaded(file_to_upload,clip_id)ifis_current:# No need to upload the file
continueprint("Uploading data for : "+my_condition+", "+my_trial+": "+file_name)dataId=api.uploadAdditionalData(file_to_upload,clip_id,data_type,file_name)
It is also possible to upload trial data and metadata in batch using information from a JSON file stored on your local machine, e.g., 'moveshelf_config_import.json'. Instead of defining a list of files_to_upload, define the path to the folder containing session data as shown below:
## General configuration. Set values before running the script
session_folder_path="<pathToDataFolder>"file_extension_to_upload="<extension>"# e.g., ".GCD"
data_file_name=None# with None, the name of the actual file is used, if needed this name can be used
data_type="raw"# Define the path to the local JSON file
local_metadata_json=os.path.join(parent_folder,"moveshelf_config_import.json")# Load JSON file
withopen(local_metadata_json,"r")asfile:local_metadata=json.load(file)# Extract conditionDefinition, representativeTrials, and trialSideSelection
# from metadata JSON
my_condition_definition=local_metadata.get("conditionDefinition",{})my_representative_trials=local_metadata.get("representativeTrials",{})my_trial_side_selection=local_metadata.get("trialSideSelection",{})## Add here the code to retrieve the project and find an existing subject and its "subject_details"
# ... subject_found = True
## Add here the code to retrieve an existing session and get its details using "getSessionById"
## Add here the code to get existing conditions and loop over conditions and trials
# ... clip_id = util.addOrGetTrial(api, session, condition, my_trial)
## Upload data
file_name=data_file_nameifdata_file_nameisnotNoneelsef"{my_trial}{file_extension_to_upload}"print("Uploading data for : "+my_condition+", "+my_trial+": "+file_name)dataId=api.uploadAdditionalData(os.path.join(session_folder_path,f"{my_trial}{file_extension_to_upload}"),clip_id,data_type,file_name)metadata_dict={"title":my_trial}# Initialize the trial template
custom_options_dict={"trialTemplate":{}}trial_template=custom_options_dict["trialTemplate"]# Add side information if available
side_value=my_trial_side_selection.get(my_trial)ifside_value:trial_template["sideAdditionalData"]={dataId:side_value}# Handle representative trial flags
representative_trial=my_representative_trials.get(my_trial,"")rep_flags={}if"left"inrepresentative_trial:rep_flags["left"]=Trueif"right"inrepresentative_trial:rep_flags["right"]=Trueifrep_flags:trial_template["representativeTrial"]=rep_flags# Remove the trialTemplate key if it's still empty
ifnottrial_template:custom_options_dict={}# Convert to JSON string
custom_options=json.dumps(custom_options_dict)api.updateClipMetadata(clip_id,metadata_dict,custom_options)# Fetch trial using the trial ID
new_clip=api.getClipData(clip_id)print(f"Found a clip with title: {new_clip['title']},\n"f"id: {new_clip['id']},\n"f"and custom options: {new_clip['customOptions']}")
PDF/image files
PDF files and image files (e.g. ".jpg" or ".png") can be stored on Movesehelf within a trial, but for this we have a dedicated place on Moveshelf, so the files are picked up e.g. when exporting to a Word document. The PDF/image files are stored in a condition called "Additional files" with a separate trial per PDF/image and a name that is typically the same as the PDF/image file name in that trial.
To upload, the code as shown above can be used, with the following modifications:
## Modifications needed to upload PDF/image files into "Additional files"
my_condition="Additional files"my_trial="<pdf_file_name>"filter_by_extension=".pdf"# for images, use e.g. ".jpg"/".png" if needed.
files_to_upload=["<path_to_additional_data.pdf>",]data_type="doc"# for images, set data_type to "img"
Raw motion data - ZIP
For raw motion data provided in a ZIP archive, we suggest to use the same "Additional files" condition that is also used for PDF/image files. Specifically, for ZIP files with raw motion data we suggest to use a trial named "Raw motion data". The additional data file can then be named e.g. "Raw motion data - my_session_name.zip".
To upload, the code as shown above can be used, with the following modifications:
## Modifications needed to upload raw motion data in ZIP archive into "Additional files"
my_condition="Additional files"my_trial="Raw motion data"data_file_name="Raw motion data - "+my_session_name+".zip"# Set to None for actual file name.
filter_by_extension=".zip"# set to None if used without filtering
files_to_upload=["<path_to_additional_data.zip>",]data_type="raw"
There are four functions available to generate different types of interactive reports:
generateAutomaticInteractiveReports to automatically generate reports using all trials of all conditions available in the session (and the previous session if applicable). Only available if automatic report generation is configured in the project.
generateConditionSummaryReport to generate a condition summary report using the specified trials.
generateCurrentSessionComparisonReport to generate a condition comparison report using the specified trials from different conditions within the same session.
generateCurrentVsPreviousSessionReport to generate a session comparison report using the specified trials from different sessions.
To create interactive reports with reference data, you need to specify the ID of the desired "norm" (i.e., reference data). The norms are stored at project level, and it is possible to access the list of norms directly from the subject_details, e.g., norm_list = subject_details["project"].get("norms", []). Select the norm you would like to use from the list, and extract its ID.
To create interactive reports, add the following lines of code to your processing script:
## README: this example shows how we can create interactive reports on Moveshelf
# using the Moveshelf API.
# This code assumes you have access to the subject_details to extract
# the norm_id (optional), the session_id, and the list of trial_ids to be
# included in the reports (see "Retrieve trials" example)
## General configuration. Set values before running the script
my_norm_id=Noneor"<normId>"# e.g. subject_details["project"]["norms"][0]["id"] (default is None for report without reference)
my_session_id="<sessionId>"# retrieve from subject_details
my_trials_ids=["<trialId1>",...,"<trialIdN>"]# list of trial/clip ids to be included in report
## Automatically create interactive reports using all trials in the specific session.
is_report_generated=api.generateAutomaticInteractiveReports(session_id=my_session_id,norm_id=my_norm_id)## It is also possible to manually create specific interactive reports
## Condition summary report
is_report_generated=api.generateConditionSummaryReport(session_id=my_session_id,title="My Condition Summary report title",trials_ids=my_trials_ids,norm_id=my_norm_id,template_id="currentSessionConditionSummaries",)## Session comparison report
is_report_generated=api.generateCurrentVsPreviousSessionReport(session_id=my_session_id,title="My Curr vs Prev report title",trials_ids=my_trials_ids,norm_id=my_norm_id,template_id="currentVsPreviousSessionComparison")## Condition comparison report
is_report_generated=api.generateCurrentSessionComparisonReport(session_id=my_session_id,title="My Condition comparison report title",trials_ids=my_trials_ids,norm_id=my_norm_id,template_id="currentSessionComparison")
Validation
To verify that the new interactive report has been successfully created, you can either check directly on Moveshelf or programmatically via the Moveshelf API.
For the manual validation, log in to Moveshelf and navigate to the relevant project, subject and session to check if the new interactive report appears.
If you prefer an automated method, add the following line of code to your processing script, right after creating the interactive report, to check if the generation was successful:
Alternatively, you can query the subject details again and verify if the new reports have been created:
# Fetch subject details using the subject ID
new_subject_details=api.getSubjectDetails(my_subject_id)reports=new_subject_details.get("reports")forreportinreports:print(f"Found interactive report with title: {report['title']} and id: {report['id']}")
Query execution time increases proportionally with the amount of data being retrieved. When you query a project with hundreds of subjects or more, it is highly recommended to retrieve a filtered subset.
This section explains how to exploit the Moveshelf API's server-side filtering functionality to retrieve a subset of subjects in a project on Moveshelf that meet a set of subject metadata, session date, and session count criteria. Filtering is particularly useful when you only need to retrieve subjects with certain characteristics (such as a specific diagnosis), or subjects that have a certain number of sessions within a specific time period.
Prerequisites
Before implementing this example, ensure that your processing script includes all necessary setup steps. In particular, you should have:
The function getFilteredProjectSubjects returns a list subjects filtered by subject metadata and by session date and session count. Subject metadata and session filters can be combined or used individually. This section explains how to construct subject metadata filters and session filters, and provides the implementation of an example use case.
Subject metadata filters can be constructed in the following way:
subject_metadata_filters={"key":"<metadata_key>"# e.g., "subject-sex"
"operator":"EQ"# currently, only EQ is supported
"value":"<metadata_value>"# e.g., "Male"
}
It is also possible to concatenate subject metadata filters with a certain logic. For example, to find all female patients diagnosed with Cerebral Palsy or ACL Rupture:
subject_metadata_filters={"logic":"AND",# Supported logics: AND, OR
"filters":[{"key":"subject-sex","operator":"EQ","value":"Female"},{"logic":"OR","filters":[{"key":"subject-diagnosis","operator":"EQ","value":"Cerebral Palsy"},{"key":"subject-diagnosis","operator":"EQ","value":"ACL Rupture"}]}]}
Session filters can be constructed in the following way. Please note that for subjects that meet the requirements defined in session_filters, ALL sessions will still be returned, as the filter operation returns a set of subjects.
session_filters={"sessionDates":{"startDate":Noneor"<startDate>"# start date (inclusive) in "YYYY-MM-DD" format or None,
"endDate":Noneor"<endDate>"# end date (inclusive) in "YYYY-MM-DD" format or None,
},"numSessions":{"min":Noneor<int># minimum number of sessions (inclusive)
"max":Noneor<int># maximum number of sessions (inclusive)
}}
To retrieve all female patients diagnosed with Cerebral Palsy or ACL Rupture with exactly two sessions between 01-01-2013 and 30-04-2020, you could use:
## README: this example shows how we can retrieve sessions from Moveshelf
# using the Moveshelf API.
## General configuration. Set values before running the script
my_project="<organizationName/projectName>"# e.g. support/demoProject
subject_metadata_filters={"logic":"AND",# Supported logics: AND, OR
"filters":[{"key":"subject-sex","operator":"EQ","value":"Female"},{"logic":"OR","filters":[{"key":"subject-diagnosis","operator":"EQ","value":"Cerebral Palsy"},{"key":"subject-diagnosis","operator":"EQ","value":"ACL Rupture"}]}]}session_filters={"sessionDates":{"startDate":"01-01-2013","endDate":"30-04-2020"},"numSessions":{"min":2,"max":2}}## Get available projects
projects=api.getUserProjects()## Select the project
project_names=[project["name"]forprojectinprojectsiflen(projects)>0]idx_my_project=project_names.index(my_project)my_project_id=projects[idx_my_project]["id"]## Get all subjects in the project that fullfill metadata criteria
## Set include_additional_data to True to also retrieve
## clips/trials and data files
subjects=api.getFilteredProjectSubjects(my_project_id,subject_metadata_filters=subject_metadata_filters,session_filters=session_filters,include_additional_data=False)
With the retrieved subset of subjects, you can proceed with further analysis. For example, you may wish to use Python to filter further by intervention metadata or session metadata, or kinematic data. Our examples below may come in helpful during the analysis, but other analysis or statistical programs such as Excel, R or SPSS may also be helpful.
To also retrieve data files (clips and additional data) for the filtered subjects, set include_additional_data=True. This is the most efficient approach for "filter once and download all" workflows:
importrequestsfromconcurrent.futuresimportThreadPoolExecutor# Use a requests.Session for connection pooling and helper functions
MAX_WORKERS=5# Number of threads for parallel processing.
POOL_MAXSIZE=MAX_WORKERS+2# Set slightly higher than max_workers to avoid connection issues
requests_session=requests.Session()adapter=requests.adapters.HTTPAdapter(pool_maxsize=POOL_MAXSIZE)requests_session.mount('https://',adapter)defdownload_with_session(url:str)->dict|None:returndownload_json_file(url,session=requests_session)defdownload_json_file(url:str,session:requests.Session|None=None)->dict|None:try:response=session.get(url)ifsessionelserequests.get(url)decoded_content=response.content.decode()returnjson.loads(decoded_content)exceptExceptionase:print(f"Failed to download or parse {url}: {e}")returnNone## Retrieve subjects with their data files
subjects=api.getFilteredProjectSubjects(my_project_id,subject_metadata_filters=subject_metadata_filters,session_filters=session_filters,include_additional_data=True# Include clips and data files
)## Collect download URLs and file paths
file_extension_to_download='.json'URLs=[]file_paths=[]forsubjectinsubjects:forsessioninsubject.get("sessions",[]):forclipinsession.get("clips",[]):foradinclip.get("additionalData",[]):ifad["originalDataDownloadUri"].endswith(file_extension_to_download):URLs.append(ad["originalDataDownloadUri"])file_paths.append(f'{clip["projectPath"]}{clip["title"]}/{ad["originalFileName"]}')# Download additional data in parallel
withThreadPoolExecutor(max_workers=MAX_WORKERS)asexecutor:additional_data=list(executor.map(download_with_session,URLs))
When defining MAX_WORKERS and POOL_MAXSIZE, make sure you add the following line after configuring and initializing the Moveshelf API: api.http.connection_pool_kw['maxsize'] = POOL_MAXSIZE .
Query execution time increases proportionally with the amount of data being retrieved. When you query a project with hundreds of sessions or more, it is highly recommended to retrieve a filtered subset.
This section explains how to exploit the Moveshelf API's server-side filtering functionality to retrieve a subset of sessions in a project on Moveshelf that meet specific subject metadata, session metadata, and date range criteria. Filtering is particularly useful when you only need to retrieve sessions with certain characteristics (such as a specific session type or medical diagnosis).
Prerequisites
Before implementing this example, ensure that your processing script includes all necessary setup steps. In particular, you should have:
The function getFilteredProjectSessions returns a list of sessions filtered by date range, session metadata, and subject metadata. For convenience, you can directly copy the URL of your filtered Sessions overview, which automatically applies all your filters.
The getFilteredProjectSessions function also accepts an optional parameter limit, an integer that specifies the maximum number of sessions to be returned. If not specified, it defaults to 500, mimicking the behavior of the Sessions overview feature. Make sure to specify a larger number if more sessions should be retrieved.
Method 1: Using sessions overview URL
This is the easiest approach. After filtering sessions in Sessions overview, simply copy the URL from your browser:
## README: this example shows how to retrieve filtered sessions from Moveshelf
# using the Moveshelf API.
## Copy the URL from your filtered sessions overview page
url="https://moveshelf.com/project/ID123/sessions?startDate=Last_year&sessioninfo-cancellation=Cancelled"## Extract project_id from URL (comes after /project/)
project_id=url.split('/project/')[1].split('/')[0]## Retrieve filtered sessions
sessions=api.getFilteredProjectSessions(project_id=project_id,session_overview_url=url)print(f"Found {len(sessions)} sessions matching the filters")
Method 2: Using explicit filters (alternative)
For programmatic control, you can specify filters explicitly.
Session metadata filters
session_metadata_filters={{"key":"<metadata_key>",# e.g., "sessioninfo-date-processing-completed"
"operator":"BETWEEN","values":"<metadata_values>"# e.g., start and end dates (inclusive) as ['YYYY-MM-DD', 'YYYY-MM-DD']
},# add more filter dicts as needed
}
Subject metadata filters
patient_metadata_filters=[{"key":"<metadata_key>",# e.g., "subject-sex",
"operator":"EQ","value":"<metadata_value>"# e.g., "Female"
},# add more filter dicts as needed
]
Supported operators include:
IN: Match any of the provided values
EQ: Match a single exact value
BETWEEN: Match a range (for dates)
Note: When building filter objects, use the key values (an array) with the IN and BETWEEN operators, and use the key value (a single value) with the EQ operator.
To also retrieve data files (clips and additional data) for the filtered sessions, set include_additional_data=True. This is the most efficient approach for "filter once and download all" workflows. You can then download and save files in parallel for maximum efficiency:
importrequestsfromconcurrent.futuresimportThreadPoolExecutor# Use a requests.Session for connection pooling and helper functions
MAX_WORKERS=5# Number of threads for parallel processing.
POOL_MAXSIZE=MAX_WORKERS+2# Set slightly higher than max_workers to avoid connection issues
requests_session=requests.Session()adapter=requests.adapters.HTTPAdapter(pool_maxsize=POOL_MAXSIZE)requests_session.mount('https://',adapter)defdownload_with_session(url:str)->dict|None:returndownload_json_file(url,session=requests_session)defdownload_json_file(url:str,session:requests.Session|None=None)->dict|None:try:response=session.get(url)ifsessionelserequests.get(url)decoded_content=response.content.decode()returnjson.loads(decoded_content)exceptExceptionase:print(f"Failed to download or parse {url}: {e}")returnNone## Retrieve sessions with their data files
sessions=api.getFilteredProjectSessions(my_project_id,start_date='2025-01-01',end_date='2025-12-31',session_metadata_filters=session_metadata_filters,patient_metadata_filters=patient_metadata_filters,include_additional_data=True# Include clips and data files
)## Collect download URLs and file paths
file_extension_to_download='.json'URLs=[]file_paths=[]forsessioninsessions:forclipinsession.get("clips",[]):foradinclip.get("additionalData",[]):ifad["originalDataDownloadUri"].endswith(file_extension_to_download):URLs.append(ad["originalDataDownloadUri"])file_paths.append(f'{clip["projectPath"]}{clip["title"]}/{ad["originalFileName"]}')# Download additional data in parallel
withThreadPoolExecutor(max_workers=MAX_WORKERS)asexecutor:additional_data=list(executor.map(download_with_session,URLs))
When defining MAX_WORKERS and POOL_MAXSIZE, make sure you add the following line after configuring and initializing the Moveshelf API: api.http.connection_pool_kw['maxsize'] = POOL_MAXSIZE .
To retrieve an existing subject, add the following lines of code to your processing script:
## README: this example shows how we can retrieve a subject from Moveshelf
# using the Moveshelf API.
# For a given project (my_project), retrieve a subject based on either the given MRN (my_subject_mrn)
# or the subject name (my_subject_name)
## General configuration. Set values before running the script
my_project="<organizationName/projectName>"# e.g. support/demoProject
my_subject_mrn="<subjectMRN>"# subject MRN, e.g. "1234567", set to None if you want to use the name
my_subject_name="<subjectName>"# subject name, set to None if you want to use the MRN
## Get available projects
projects=api.getUserProjects()## Select the project
project_names=[project["name"]forprojectinprojectsiflen(projects)>0]idx_my_project=project_names.index(my_project)my_project_id=projects[idx_my_project]["id"]## Find the subject based on MRN or name
subject_found=Falseifmy_subject_mrnisnotNone:subject=api.getProjectSubjectByEhrId(my_subject_mrn,my_project_id)ifsubjectisnotNone:subject_found=Trueifnotsubject_foundandmy_subject_nameisnotNone:subjects=api.getProjectSubjects(my_project_id)forsubjectinsubjects:ifmy_subject_name==subject['name']:subject_found=Truebreakifmy_subject_mrnisNoneandmy_subject_nameisNone:print("We need either subject mrn or name to be defined to be able to search for the subject.")## Print message
ifsubject_found:subject_details=api.getSubjectDetails(subject["id"])subject_metadata=json.loads(subject_details.get("metadata","{}"))print(f"Found subject with name: {subject_details['name']},\n"f"id: {subject_details['id']}, \n"f"and MRN: {subject_metadata.get('ehr-id',None)}")else:print(f"Couldn't find subject with MRN: {my_subject_mrn},\n"f"in project: {my_project}")
To retrieve subject metadata from an existing subject, add the following lines of code to your processing script:
## README: this example shows how we can retrieve subject metadata from an existing subject on
# Moveshelf using the Moveshelf Python API.
# This code assumes you have implemented the 'Retrieve subject' example, and that you have found
# the subject with a given EHR-id/MRN (my_subject_mrn) or name (my_subject_name) within a given
# project (my_project), that you have access to the subject ID and obtained the "subject_details"
## General configuration. Set values before running the script
my_project="<organizationName/projectName>"# e.g. support/demoProject
my_subject_mrn="<subjectMRN>"# subject MRN, e.g. "1234567" or None
my_subject_name="<subjectName>"# subject name, e.g. Subject1 or None
## Add here the code to retrieve the project and get the "subject_details" for that subject
subject_metadata=json.loads(subject_details.get("metadata","{}"))print(f"Found subject with name: {subject_details['name']},\n"f"id: {subject_details['id']}, \n"f"and metadata: {subject_metadata}")
To retrieve a session with a specific date from a subject, add the following lines of code to your processing script:
## README: this example shows how we can retrieve sessions from Moveshelf
# using the Moveshelf API.
# This code assumes you have implemented the 'Retrieve subject' example, and
# that you have found the subject with a given EHR-id/MRN (my_subject_mrn)
# or name (my_subject_name) within a given project (my_project), and that you
# have access to the subject ID.
# Then, for that subject, retrieve the specified session (my_session_name).
## General configuration. Set values before running the script
my_project="<organizationName/projectName>"# e.g. support/demoProject
my_subject_mrn="<subjectMRN>"# subject MRN, e.g. "1234567" or None
my_subject_name="<subjectName>"# subject name, e.g. Subject1 or None
my_session_name="<sessionDate>"# "YYYY-MM-DD" format
## Add here the code to retrieve the project and find an existing subject and its "subject_details"
# ... subject_found = True
## Get sessions
sessions=subject_details.get("sessions",[])# Loop over sessions
session_found=Falseforsessioninsessions:try:session_name=session["projectPath"].split("/")[2]except:session_name=""ifsession_name==my_session_name:session_found=Truesession_id=session["id"]print(f"Found session with projectPath: {session['projectPath']},\n"f"and id: {session_id}")breakifnotsession_found:print(f"Couldn't find session: {my_session_name},\n"f"for subject with MRN: {my_subject_mrn}")
This section explains how to retrieve session metadata for a specified session for a subject with a specified MRN on Moveshelf using the Moveshelf API.
Prerequisites
Before implementing this example, ensure that your processing script includes all necessary setup steps. In particular, you should have:
To retrieve session metadata from a specific session and subject, add the following lines of code to your processing script:
## README: this example shows how we can retrieve session metadata from Moveshelf
# using the Moveshelf API.
# This code assumes you have implemented the 'Retrieve sessopm' example, and
# that you have found session (my_session_name) for the subject with a given EHR-id/MRN
# (my_subject_mrn) or name (my_subject_name) within a given project (my_project), and
# that you have access to the session ID.
## General configuration. Set values before running the script
my_project="<organizationName/projectName>"# e.g. support/demoProject
my_subject_mrn="<subjectMRN>"# subject MRN, e.g. "1234567" or None
my_subject_name="<subjectName>"# subject name, e.g. Subject1 or None
my_session_name="<sessionDate>"# "YYYY-MM-DD" format
## Add here the code to retrieve the project and find an existing subject and session using "getSessionById"
session_id=session["id"]session_metadata=session.get("metadata",None)print(f"Found session with projectPath: {session['projectPath']},\n"f"id: {session_id},\n"f"and metadata: {session_metadata}")
To export subject and session metadata to an Excel spreadsheet, add the following lines of code to your processing script, right after having Retrieved a subject or list of subjects, OR Retrieved a session or list of sessions. The example uses the MetadataExcelExporter class which can be found in the utils folder as part of metadata_excel_exporter.py in our public GitHub repository. Copy the utils folder inside your work environment and add the following lines of code to your processing script:
fromutilsimportMetadataExcelExporter## ============================================================================
## CONFIGURATION VARIABLES - Edit these before running
## ============================================================================
OUTPUT_FILENAME="Metadata_Export.xlsx"# Specify which fields to export (leave empty for all)
SUBJECT_METADATA_FIELDS:list[str]=['ehr-id','subject-diagnosis']SESSION_METADATA_FIELDS:list[str]=['vicon-height','vicon-weight','interview-assistive-device']# Column header format configuration
# When True: Use metadata field IDs as column headers
# (e.g., 'sessioninfo-comments', 'vicon-leg-length-right')
# When False: Use descriptive labels with tab context
# (e.g., 'Session info: Comments', 'Physical exam 1: Leg length (mm) - right')
USE_METADATA_ID_AS_COLUMN_HEADER:bool=True# Create exporter instance
exporter=MetadataExcelExporter(api,use_metadata_id_as_column_header=USE_METADATA_ID_AS_COLUMN_HEADER)# Export metadata. Uncomment one of the following options (Option 1 or Option 2)
# # Option 1: Export metadata for a list of subjects
# subjects_list = subjects # e.g., the output from Retrieving a subset of subjects
## Note: It is also possible to export metadata from a single subject by assigning
## subjects_list = [subject_details] # where subject_details results from the Retrieve a subject example
# exporter.export_metadata_to_excel(
# project_id=my_project_id,
# output_filename=OUTPUT_FILENAME,
# subjects_list=subjects_list,
# subject_fields=SUBJECT_METADATA_FIELDS,
# session_fields=SESSION_METADATA_FIELDS
# )
# # Option 2: Export metadata for a list of sessions
# # Sessions will be automatically grouped by patient in export_metadata_to_excel
# sessions_list = sessions # e.g., the output from Retrieving a subset of sessions
## Note: It is also possible to export metadata from a single session by assigning
## sessions_list = [session] # where session results from the Retrieve a session example
# exporter.export_metadata_to_excel(
# project_id=my_project_id,
# output_filename=OUTPUT_FILENAME,
# sessions_list=sessions_list,
# subject_fields=SUBJECT_METADATA_FIELDS,
# session_fields=SESSION_METADATA_FIELDS
# )
To display descriptive labels as column headers instead of unique metadata field IDs, set USE_METADATA_ID_AS_COLUMN_HEADER to False.
This section explains how to retrieve trials within a specific condition of a specific session for a subject with a specified MRN on Moveshelf using the Moveshelf API.
Prerequisites
Before implementing this example, ensure that your processing script includes all necessary setup steps. In particular, you should have:
To retrieve the trials within a specific condition, add the following lines of code to your processing script:
## README: this example shows how we can retrieve trials from Moveshelf
# using the Moveshelf API.
# This code assumes you have implemented the 'Retrieve subject' example,
# that you have found the subject with a given EHR-id/MRN (my_subject_mrn)
# or name (my_subject_name) within a given project (my_project), that you
# have access to the subject ID, and you have implemented the
# 'Retrieve session' example to retrieve the specified session (my_session_name).
## General configuration. Set values before running the script
my_project="<organizationName/projectName>"# e.g. support/demoProject
my_subject_mrn="<subjectMRN>"# subject MRN, e.g. "1234567" or None
my_subject_name="<subjectName>"# subject name, e.g. Subject1 or None
my_session_name="<sessionDate>"# "YYYY-MM-DD" format
my_condition="<conditionName>"# e.g. "Barefoot"
## Add here the code to retrieve the project and find an existing subject and its "subject_details"
# ... subject_found = True
## Add here the code to retrieve an existing session and get its details using "getSessionById"
# Get conditions in the session
conditions=[]conditions=util.getConditionsFromSession(session,conditions)condition_exists=any(c["path"].replace("/","")==my_conditionforcinconditions)condition=next(cforcinconditionsifc["path"].replace("/","")==my_condition) \
ifcondition_existselse{"path":my_condition,"clips":[]}trial_count=len(condition["clips"])ifcondition_existselse0clips_in_condition=[clipforclipincondition["clips"]]ifcondition_existsandtrial_count>0else[]# get the id and title of each clip
forclipinclips_in_condition:clip_id=clip["id"]clip_title=clip["title"]print(f"Found a clip with title: {clip_title},\n"f"and id: {clip_id}")
This section explains how to retrieve data (files) within a specific trial of a condition within a session of a subject (specified by MRN) on Moveshelf using the Moveshelf API.
Prerequisites
Before implementing this example, ensure that your processing script includes all necessary setup steps. In particular, you should have:
To retrieve the additional data files with that trial, add the following lines of code to your processing script:
## README: this example shows how we can retrieve additional data from
# Moveshelf using the Moveshelf API.
# This code assumes you have implemented the 'Retrieve subject' example,
# that you have found the subject with a given EHR-id/MRN (my_subject_mrn)
# or name (my_subject_name) within a given project (my_project), that you
# have access to the subject ID, you have implemented the 'Retrieve session'
# example, and you have implemented the 'Retrieve trial' example to get or
# create the specified trial (my_trial) within a specific condition (my_condition).
## Import necessary modules
importrequests# Used to send HTTP requests to retrieve additional data files from Moveshelf
## General configuration. Set values before running the script
my_project="<organizationName/projectName>"# e.g. support/demoProject
my_subject_mrn="<subjectMRN>"# subject MRN, e.g. "1234567" or None
my_subject_name="<subjectName>"# subject name, e.g. Subject1 or None
my_session_name="<sessionDate>"# "YYYY-MM-DD" format
my_condition="<conditionName>"# e.g. "Barefoot"
my_trial="<trialName>"filter_by_extension=None## Add here the code to retrieve the project and find an existing subject and its "subject_details"
# ... subject_found = True
## Add here the code to retrieve an existing session and get its details using "getSessionById"
## Add here the code to retrieve an existing trial and get the ID: clip_id
# get all additional data
existing_additional_data=api.getAdditionalData(clip_id)# if filter_by_extension is provided, only get the data with that extension
existing_additional_data=[datafordatainexisting_additional_dataifnotfilter_by_extensionoros.path.splitext(data["originalFileName"])[1].lower()==filter_by_extension]existing_file_names=[data["originalFileName"]fordatainexisting_additional_dataiflen(existing_additional_data)>0]print("Existing data for clip: ")print(*existing_file_names,sep="\n")# Loop through the data found, and download if the "uploadStatus" is set to "Complete"
# The data will be available in "file_data", from which it can e.g. be used to
# process, or written to a file on local storage
fordatainexisting_additional_data:ifdata["uploadStatus"]=="Complete":file_data=requests.get(data["originalDataDownloadUri"]).content
PDF/image files
PDF files and image files (e.g. ".jpg" or ".png") can be stored as part of a trial and retrieved following the example before, but on Moveshelf we have a dedicated place for PDF/image files, so these are picked up e.g. when exporting to a Word document.
For this, PDF/image files are stored in a condition called "Additional files" with a trial per PDF/image and a name that is typically the same as the PDF/image file name in that trial.
To retrieve, the code as shown above can be used, with the following modifications:
## Modifications needed to extract PDF/image files stored within "Additional files"
my_condition="Additional files"filter_by_extension=".pdf"# to be modified based on the required extension
Raw motion data - ZIP
For raw motion data provided in a ZIP archive, we suggest to use the same "Additional files" condition that is also used for PDF/image files. Specifically, for ZIP files with raw motion data we suggest to use a trial named "Raw motion data". The code to retrieve the data from this trial is similar to the PDF/image example above, but this time specify the specific trial name my_trial you first search for the specific trial:
## Modifications needed to extract ZIP files stored within "Additional files"
my_condition="Additional files"my_trial="Raw motion data"# To be modified based on the exact trial that is required.
filter_by_extension=".zip"# set to None to get all data in the trial
To delete an existing subject, add the following lines of code to your processing script:
## README: this example shows how we can delete a subject from Moveshelf
# using the Moveshelf API.
# Delete a subject by ID
subject_id="<subjectId>"# subject["id"]
result=api.deleteSubject(subject_id)ifresult:print(f"Subject {subject_id} deleted successfully")else:print(f"Failed to delete subject {subject_id}")
To delete multiple subjects, add the following lines of code to your processing script:
## README: this example shows how we can delete multiple subjects from Moveshelf
# using the Moveshelf API.
# Delete multiple subjects at once
subject_ids=["<subjectId_1>","<subjectId_2>","<subjectId_3>"]results=api.deleteSubjects(subject_ids)# Check results
forsubject_id,successinresults.items():status="SUCCESS"ifsuccesselse"FAILED"print(f"Subject {subject_id}: {status}")# Count successes and failures
successful=sum(results.values())total=len(subject_ids)print(f"Deleted {successful}/{total} subjects successfully")
To delete an existing session, add the following lines of code to your processing script:
## README: this example shows how we can delete a session from Moveshelf
# using the Moveshelf API.
# Delete a session by ID
session_id="<sessionId>"# session["id"]
result=api.deleteSession(session_id)ifresult:print(f"Session {session_id} deleted successfully")else:print(f"Failed to delete session {session_id}")
To delete an existing trial, add the following lines of code to your processing script:
## README: this example shows how we can delete a trial from Moveshelf
# using the Moveshelf API.
# Delete a trial (clip) by ID
clip_id="<clipId>"# clip["id"]
result=api.deleteClip(clip_id)ifresult:print(f"Trial {clip_id} deleted successfully")else:print(f"Failed to delete trial {clip_id}")
This section explains how to delete all trials within a specified condition from Moveshelf using the Moveshelf API, based on the session's ID and the condition name.
Prerequisites
Before implementing this example, ensure that your processing script includes all necessary setup steps. In particular, you should have:
To delete all trials within an existing condition, add the following lines of code to your processing script:
## README: this example shows how we can delete all trials/clips within
# a condition from Moveshelf using the Moveshelf API.
# Delete all trials within a condition
session_id="<sessionId>"# session["id"]
condition_name="<conditionName>"# e.g., "Barefoot"
result=api.deleteClipByCondition(session_id,condition_name)print(f"Deletion Results:")print(f" Successfully deleted: {result['deleted_count']} trials")print(f" Failed to delete: {result['failed_count']} trials")# Show detailed results
fordetailinresult['details']:status="✓"ifdetail['deleted']else"✗"print(f" {status}{detail['title']} ({detail['clip_id']})")
To delete an existing data file, add the following lines of code to your processing script:
## README: this example shows how we can delete a specific data
# file from Moveshelf using the Moveshelf API.
# Delete additional data by ID
additional_data_id="<additionalDataId>"# additional_data["id"]
result=api.deleteAdditionalData(additional_data_id)ifresult:print(f"File {additional_data_id} deleted successfully")else:print(f"Failed to delete file {additional_data_id}")
Moveshelf provides a public GitHub repository that contains several
complete example scripts that are ready to be used.
Follow the steps in this section to run an example of querying and downloading data from the Moveshelf platform, i.e., download_data.py.
This section explains how to retrieve data (files) for all subjects in a project on Moveshelf using the Moveshelf API in an efficient way. The key points to speed up execution in this use case are:
Reduce the number of API calls to retrieve data
Download data in parallel
When to use parallel retrieval by Subject or Session ID: Use this pattern when (1) you already have a list of specific IDs to retrieve, (2) you need to perform multiple filtering iterations before downloading data, or (3) you need to programmatically select which items to download. For simple "filter once and download all" workflows, using include_additional_data=True directly in getFilteredProjectSubjects or getFilteredProjectSessions is more efficient with fewer API calls.
Prerequisites
Before implementing these examples, ensure that your processing script includes all necessary setup steps. In particular, you should have:
Below are two recommended patterns for retrieving large numbers of files in parallel. Use whichever matches your workflow.
Example 1: Retrieve subject data in parallel (from a list of subject IDs)
Use this pattern when you have a list of subject IDs and need to retrieve full subject data with all sessions, clips, and additional data files. Subject IDs can be obtained from filtered subjects, manual selection, or other custom sources.
importos,sys,jsonparent_folder=os.path.dirname(os.path.dirname(__file__))sys.path.append(parent_folder)importrequestsfrommoveshelf_api.apiimportMoveshelfApifromconcurrent.futuresimportThreadPoolExecutor# Use a requests.Session for connection pooling
MAX_WORKERS=5# Number of threads for parallel processing.
POOL_MAXSIZE=MAX_WORKERS+2# Set slightly higher than max_workers to avoid connection issues
requests_session=requests.Session()adapter=requests.adapters.HTTPAdapter(pool_maxsize=POOL_MAXSIZE)requests_session.mount('https://',adapter)defdownload_with_session(url:str)->dict|None:returndownload_json_file(url,session=requests_session)defdownload_json_file(url:str,session:requests.Session|None=None)->dict|None:try:response=session.get(url)ifsessionelserequests.get(url)decoded_content=response.content.decode()returnjson.loads(decoded_content)exceptExceptionase:print(f"Failed to download or parse {url}: {e}")returnNone## Setup the API
# Load config
personal_config=os.path.join(parent_folder,"mvshlf-config.json")ifnotos.path.isfile(personal_config):raiseFileNotFoundError(f"Configuration file '{personal_config}' is missing.\n""Ensure the file exists with the correct name and path.")withopen(personal_config,"r")asconfig_file:data=json.load(config_file)api=MoveshelfApi(api_key_file=os.path.join(parent_folder,data["apiKeyFileName"]),api_url=data["apiUrl"],)# Increase connection pool size globally for urllib3 to match MAX_WORKERS thread workers
api.http.connection_pool_kw['maxsize']=POOL_MAXSIZE## Get available projects
projects=api.getUserProjects()project_names=[project['name']forprojectinprojectsiflen(projects)>0]my_project="<organizationName/projectName>"# e.g. support/demoProject
idx_my_project=project_names.index(my_project)my_project_id=projects[idx_my_project]["id"]file_extension_to_download='.json'# Only download json files
# Example: List of subject IDs (see note below on how to obtain these through filtering)
subject_ids=["<subjectId_1>","<subjectId_2>","<subjectId_3>"]print(f"Processing {len(subject_ids)} subjects")# Step 1: Retrieve full subject data in parallel
withThreadPoolExecutor(max_workers=MAX_WORKERS)asexecutor:subjects_with_clips=list(executor.map(api.getSubjectData,subject_ids))## Extract URLs and file paths for additional data
URLs=[]file_paths=[]forsubject_detailsinsubjects_with_clips:forsessioninsubject_details.get("sessions",[]):forclipinsession.get("clips",[]):foradinclip.get("additionalData",[]):ifad["originalDataDownloadUri"].endswith(file_extension_to_download):URLs.append(ad["originalDataDownloadUri"])file_paths.append(f'{clip["projectPath"]}{clip["title"]}/{ad["originalFileName"]}')print(f"Found {len(URLs)} files to download")# Step 2: Download additional data files in parallel
withThreadPoolExecutor(max_workers=MAX_WORKERS)asexecutor:additional_data=list(executor.map(download_with_session,URLs))print(f"Downloaded {sum(1fordatainadditional_dataifdataisnotNone)} files successfully")
How to obtain subject IDs: You can retrieve subject IDs by using getFilteredProjectSubjects with include_additional_data=False for fast filtering, then extract the IDs with: subject_ids = [subject['id'] for subject in filtered_subjects]. This is useful when you need to iterate through multiple filters or programmatically select which subjects to download before retrieving their data.
Example 2: Retrieve session data in parallel (from a list of session IDs)
Use this pattern when you have a list of session IDs and need to retrieve session data with clips and additional data files. Session IDs can be obtained from filtered sessions, manual selection, or other custom sources.
importos,sys,jsonparent_folder=os.path.dirname(os.path.dirname(__file__))sys.path.append(parent_folder)importrequestsfrommoveshelf_api.apiimportMoveshelfApifromconcurrent.futuresimportThreadPoolExecutor# Use a requests.Session for connection pooling
MAX_WORKERS=5# Number of threads for parallel processing.
POOL_MAXSIZE=MAX_WORKERS+2# Set slightly higher than max_workers to avoid connection issues
requests_session=requests.Session()adapter=requests.adapters.HTTPAdapter(pool_maxsize=POOL_MAXSIZE)requests_session.mount('https://',adapter)defdownload_with_session(url:str)->dict|None:returndownload_json_file(url,session=requests_session)defdownload_json_file(url:str,session:requests.Session|None=None)->dict|None:try:response=session.get(url)ifsessionelserequests.get(url)decoded_content=response.content.decode()returnjson.loads(decoded_content)exceptExceptionase:print(f"Failed to download or parse {url}: {e}")returnNone## Setup the API
# Load config
personal_config=os.path.join(parent_folder,"mvshlf-config.json")ifnotos.path.isfile(personal_config):raiseFileNotFoundError(f"Configuration file '{personal_config}' is missing.\n""Ensure the file exists with the correct name and path.")withopen(personal_config,"r")asconfig_file:data=json.load(config_file)api=MoveshelfApi(api_key_file=os.path.join(parent_folder,data["apiKeyFileName"]),api_url=data["apiUrl"],)# Increase connection pool size globally for urllib3 to match MAX_WORKERS thread workers
api.http.connection_pool_kw['maxsize']=POOL_MAXSIZE## Get available projects
projects=api.getUserProjects()project_names=[project['name']forprojectinprojectsiflen(projects)>0]my_project="<organizationName/projectName>"# e.g. support/demoProject
idx_my_project=project_names.index(my_project)my_project_id=projects[idx_my_project]["id"]file_extension_to_download='.json'# Only download json files
# Example: List of session IDs (see note below on how to obtain these through filtering)
session_ids=["<sessionId_1>","<sessionId_2>","<sessionId_3>"]print(f"Processing {len(session_ids)} sessions")# Step 1: Retrieve session data with additional data in parallel
withThreadPoolExecutor(max_workers=MAX_WORKERS)asexecutor:sessions_with_data=list(executor.map(lambdasid:api.getSessionById(sid,include_additional_data=True),session_ids))## Extract URLs and file paths for additional data
URLs=[]file_paths=[]forsessioninsessions_with_data:forclipinsession.get("clips",[]):foradinclip.get("additionalData",[]):ifad["originalDataDownloadUri"].endswith(file_extension_to_download):URLs.append(ad["originalDataDownloadUri"])file_paths.append(f'{clip["projectPath"]}{clip["title"]}/{ad["originalFileName"]}')print(f"Found {len(URLs)} files to download")# Step 2: Download additional data files in parallel
withThreadPoolExecutor(max_workers=MAX_WORKERS)asexecutor:additional_data=list(executor.map(download_with_session,URLs))print(f"Downloaded {sum(1fordatainadditional_dataifdataisnotNone)} files successfully")
How to obtain session IDs: You can retrieve session IDs by using getFilteredProjectSessions with include_additional_data=False for fast filtering, then extract the IDs with: session_ids = [session['id'] for session in filtered_sessions]. This is useful when you need to iterate through multiple filters or programmatically select which sessions to download before retrieving their data.
Moveshelf provides a public GitHub repository that contains several
complete example scripts that are ready to be used.
Follow the steps in this section to run an example of querying and downloading data from the Moveshelf platform, i.e., pre_vs_post_intervention_query_example.py.
In this example we provide a complete workflow for analyzing intervention effects. This includes defining clear inclusion and exclusion criteria for subjects, sessions, and clips/trials, applying efficient server-side filtering to narrow down relevant data, and performing additional local filtering in Python for more advanced logic. The script also demonstrates how to identify and extract consecutive sessions surrounding a specific intervention (e.g., sessions immediately before and after), and how to organize and export the resulting dataset to an Excel file for further analysis or reporting. Refer to the script's README section for detailed instructions and explanation.
Open pre_vs_post_intervention_query_example.py in Visual Studio Code, follow the instructions detailed in the README section, add all relevant information to the script and save the file
To run the script, press F5 or type python scripts/pre_vs_post_intervention_query_example.py in the terminal and press 'Enter'
If you need queries that are not included in the Moveshelf API, you can create a custom API wrapper that extends it with custom GraphQL queries. This section demonstrates how to create a custom API wrapper defining a new method (getProjectSubjectsWithAdditionalData) to retrieve, for a given project, all subjects' name, ID, and metadata, and all their sessions' ID, date, and metadata.
Create a custom API wrapper:
Create a new Python file (in this example we call it api.py and place it inside a folder called 'api' in the root folder), and define a subclass of MoveshelfApi (see code snippet below). This allows you to extend the existing API by adding custom GraphQL queries. For example, the built-in getProjectSubjects function only retrieves subject names and IDs. In the example below, we define getProjectSubjectsWithAdditionalData, that extends the built-in getProjectSubjects function to also retrieve subject metadata, session details (ID, date, and metadata) and URLs for additional data (i.e., files).
frommoveshelf_api.apiimportMoveshelfApi# Custom Moveshelf API class that extends the existing API
classMoveshelfApiCustomized(MoveshelfApi):defgetProjectSubjectsWithAdditionalData(self,project_id:str):data=self._dispatch_graphql('''
query getProjectPatients($projectId: ID!) {
node(id: $projectId) {
... on Project {
id
name
description
configuration
canEdit
template {
name
data
}
patients {
id
name
metadata
project {
id
}
sessions {
id
projectPath
clips {
id
title
created
projectPath
uploadStatus
hasCharts
additionalData {
id
dataType
uploadStatus
originalFileName
originalDataDownloadUri
}
}
}
}
norms {
id
projectPath
}
}
}
}
''',projectId=project_id)returndata['node']['patients']
Use the custom API in your processing script:
To use your extended API, import the custom class into your processing script. The example below shows how to call getProjectSubjectsWithAdditionalData to retrieve metadata for all subjects and their sessions.
parent_folder=os.path.dirname(os.path.dirname(__file__))sys.path.append(parent_folder)fromapi.apiimportMoveshelfApiCustomized## Setup the API
# Load config
personal_config=os.path.join(parent_folder,"mvshlf-config.json")ifnotos.path.isfile(personal_config):raiseFileNotFoundError(f"Configuration file '{personal_config}' is missing.\n""Ensure the file exists with the correct name and path.")withopen(personal_config,"r")asconfig_file:data=json.load(config_file)# Use custom API
api=MoveshelfApiCustomized(api_key_file=os.path.join(parent_folder,data["apiKeyFileName"]),api_url=data["apiUrl"])## General configuration. Set values before running the script
my_project="<organizationName/projectName>"# e.g. support/demoProject
## Get available projects
projects=api.getUserProjects()## Select the project
project_names=[project["name"]forprojectinprojectsiflen(projects)>0]idx_my_project=project_names.index(my_project)my_project_id=projects[idx_my_project]["id"]# Custom query (defined in ../api/api.py) that extracts the metadata of all patients
# and the metadata of all their sessions within a given project
subjects=api.getProjectSubjectsWithAdditionalData(my_project_id)# Print the subject data
forsubjectinsubjects:print(f"Subject: {subject['name']} (ID: {subject['id']})")print(f"Metadata: {subject['metadata']}")print("Sessions:")forsessioninsubject['sessions']:print(f" - Session {session['id']} on {session['date']} with metadata: {session['metadata']}")
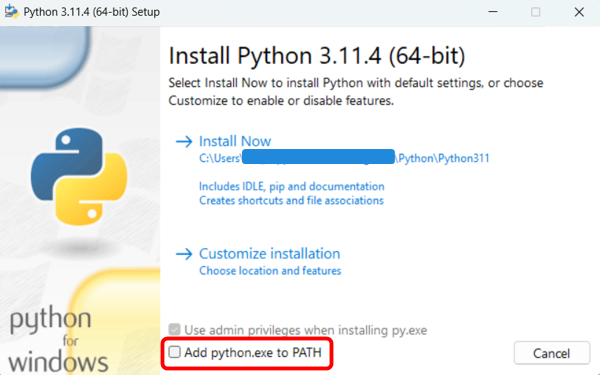
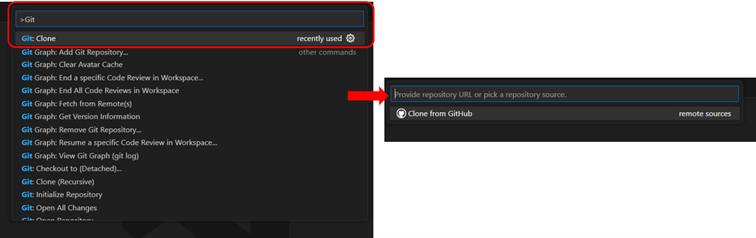

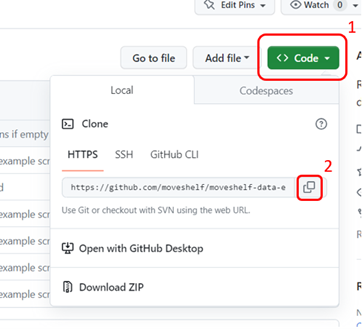
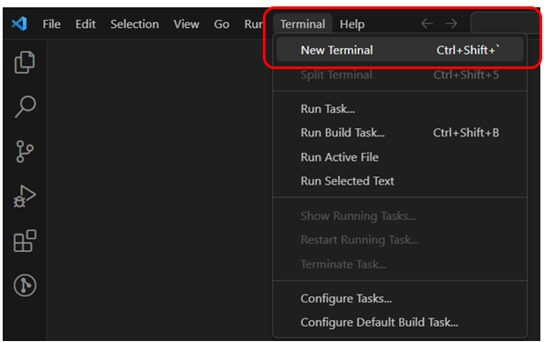
 Important: The keys in the metadata dictionary to be imported must match the metadata template that is configured for the Moveshelf project you want to import to. You can download the configured metadata template from the project overview.
Important: The keys in the metadata dictionary to be imported must match the metadata template that is configured for the Moveshelf project you want to import to. You can download the configured metadata template from the project overview.
